
背景
底层 LLM 的军备竞赛正在如火如荼地进行着,上层的产品能力似乎也还没得到释放,做来做去就是聊天工具、RAG问答,但似乎这里还有一块基础能力亟待填补 —— LLM on device(端侧大模型)。
安卓 OS 不断渗透到电视、车机、广告屏,本质上还是我们需要特定场景下的智能设备;或者是把一部分专门的能力剥离成一个独立的设备,诸如树莓派、机顶盒、蓝光播放器、声卡。这些设备形态的底层逻辑是:
具有独立的使用场景
支持运行程序
而大模型其实就是一种特殊的 OS,因此自然而然地就可以联想到,未来会有越来越多的大模型被移植到我们身边随处可见的智能设备上,小到一个闸机,大到航天军工,LLM on Device 一定是必然趋势。但不是说所有场景全部会变成本地,而是端云协同,端上解决必要的、轻量的任务,云端解决复杂的、耗时的任务。云+端,会是未来 AI 的必然方向,正如那句成年人不做选择,我全都要。
意义
端侧大模型的意义主要体现在以下几个方面:
提高用户体验:通过在手机等设备上直接运行端侧大模型,可以实现更快速、更准确的用户需求理解和服务,提升用户体验
保护隐私信息:端侧大模型能够在不上传个人数据到云端的情况下使用,从而在保护隐私信息方面具有优势
降低算力成本:端侧大模型有助于解决算力成本问题,通过优化计算资源的使用,实现任务负载分配和降本增效
支持规模化应用:端侧AI支撑规模化扩张,有助于人工智能在用户软件使用方式上带来根本性变革
推动 AI 技术渗透到社会每个角落:随着端侧大模型不断下放到各种设备,平时车站咨询台的工作人员全部可以换成 AI 机器人;类似的还有导游、咨询师、门诊问诊等职业(但我觉得在中国很难大面积普及,因为这可能不利于就业)
实战
语言
既然要跨平台移植,那必须首选 C++ 这位老选手了。有句话叫流水的高级语言,铁打的 C++。纵观涉及到底层能力或是多平台移植的需求,都能看到 C++ 的身影。因此业界最流行的一些通用能力库,都有对应的 C++ 版本。
开源方案对比
mlx:可以理解为 NumPy 的 C++ 版本,都是用来处理数值计算(多维数组)和科学计算(线性代数运算),所以凡是涉及到处理大量数据的工作都适用,不仅局限于机器学习领域(还包括比如数据科学)。只不过 NumPy 是 python,MLX 用 C++ 实现,并且对 Apple 平台的芯片做了优化,可以充分释放 Apple 芯片的潜力。这么一来,就可以用来把模型移植到 Apple 平台,因为模型的推理本质上还是在做数组运算。另外,mlx 还提供了 C 语言接口和 Swift 接口。
llama.cpp:则是用 C++ 从头到尾撸了一个 Transformer 推理框架,依赖极少,支持 CPU 推理,当然也支持各种底层库推理(CUDA/OpenCL),具有 FP16 和 FP32 的混合精度、支持8/4bit量化等等。
mlc-llm: 和 llama.cpp 类似的跨平台推理框架,号称性能远超 llama.cpp,
当然其实还有好几个类似的框架,比如 tgi、lightllm、vllm、exllamav2(only server)、FasterTransformer、FlashAttention 等等,各有优缺点,就不一一举例了。按社区的热度、生态、性能、功能来看目前 llama.cpp 绝对是遥遥领先(颇有种17年torch、keras、caffe、mxnet、tensorflow...群雄逐鹿的阵势),本文主要讨论 mlx、llama.cpp、mlc-llm,主要评测三款推理框架在 Mac、iPhone 设备上的性能。
Mac: Apple M1,16G, macOS13.5
iPhone: A16, 6G(iPhone14 Pro\iPhone 15)

评分标准:优秀 5 —— 0 差
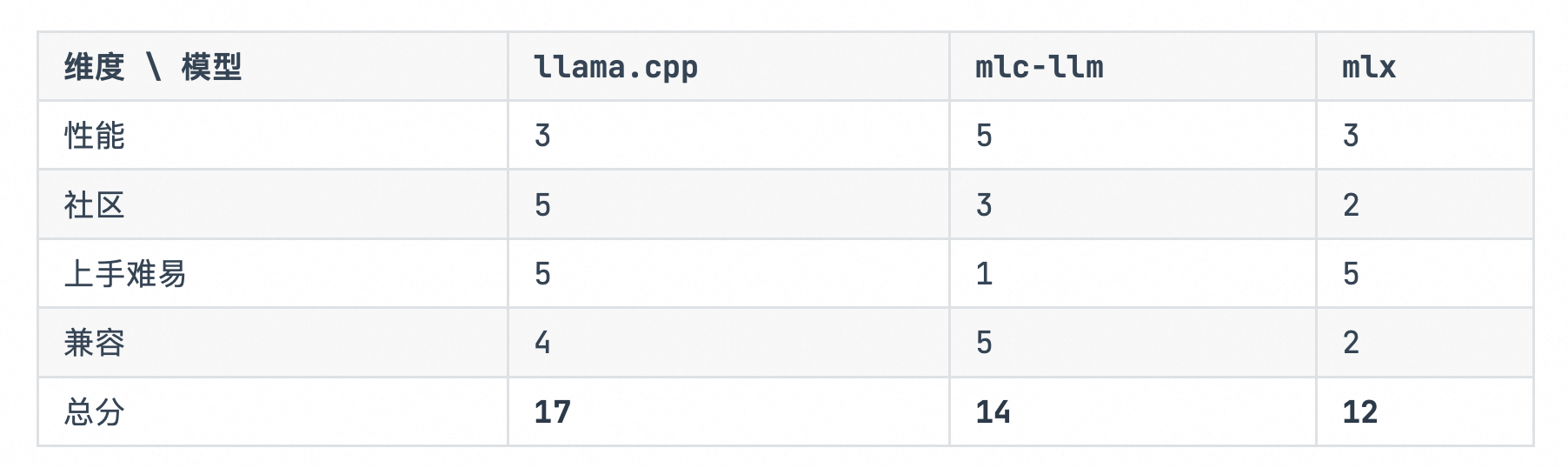
mlc-llm: 性能最强;文档优秀;兼容设备最广;但社区不怎么活跃,bug 多,模型转化繁琐;
llama-cpp: 社区最活跃;性能一般;支持模型多;部署简单
mlx: 性能一般;苹果生态友好;无法兼容其他生态;
llama.cpp
把 LLM 跑在 macOS, Linux, and Windows,用 C++ 实现。目前使用范围最广的端侧大模型部署方案,是许多项目源头。
架构特点
llama.cpp 无需任何额外依赖,可以直接编译出可执行文件,这使得它相比 Python 代码对 PyTorch 等库的要求更为简便
它支持将模型参数从32位浮点数转换为16位甚至8、4位整数,以实现模型的量化
llama.cpp 支持 CPU 推理,并且也支持各种底层库推理(如CUDA/OpenCL),这表明它具有良好的兼容性和灵活性
由于没有依赖其他深度学习框架结构,llama.cpp 需要自己从头建图,完成数据流转、串联算子、调度运算等一系列基础工作,同时还要兼顾速度性能。相当于实现了一
llama.cpp 还提供了服务化组件,可以用于构建HTTP API服务和与之交互的简单web前端
mlc-llm
和 llama.cpp 同属底层推理框架,可以把 LLM 直接跑在 laptops/servers(Nvidia/AMD/Apple), iPhone, Android, and Chrome browser 上。比 llama.cpp 适配更多平台,且性能也好于 llama.cpp。
mlc 有专门的权重格式,你需要做一些额外的操作才能把目前公开的 LLM 移植到上面。当然它同样也提供了预编译好的模型。
两个关键原料
要在 mlc-llm 下面跑起来,你需要两部分原料。如果是主流的模型,官方提供了现成的,如下:
- 模型权重转换为 MLC 格式(例如 RedPajama-INCITE-Chat-3B-v1-q4f16_1-MLC)
如何把通用的 .safetensors 模型转成上面的 mlc 格式呢?官方也提供了脚本和文档 https://llm.mlc.ai/docs/compilation/convert_weights.html(u1s1,mlc-llm 的文档还是非常完整的)
mlc_chat convert_weight ./dist/models/phi-2/ \
--quantization q4f16_1 \
-o dist/phi-2-q4f16_1-MLC
- 包含推理逻辑的模型库(请参阅 repo binary-mlc-llm-libs)

一个模型库包含的东西如下:
模型架构(例如,mistral、phi-msft)
量化方案(例如 q3f16_1、q0f32)
影响内存规划的元数据(例如 context_window_size、sliding_window_size、prefill_chunk_size)
平台(例如 cuda、webgpu、iphone、android)
如果是自己的模型,如何编译上面的二进制文件呢?需要手动操作:https://llm.mlc.ai/docs/compilation/compile_models.html
mlc_chat compile ./dist/phi-2-q4f16_1-MLC/mlc-chat-config.json \
--device iphone -o dist/libs/phi-2-q4f16_1-iphone.tar
组装成静态库
文档:https://llm.mlc.ai/docs/deploy/ios.html#id3
出了准备上面两部分原料,还需要一个轻量的运行时和 tokenizer,把上面两个原料打成一个静态库
最后打出来的产物如下:
>>> ls ./build/lib/
libmlc_llm.a # A lightweight interface to interact with LLM, tokenizer, and TVM Unity runtime
libmodel_iphone.a # The compiled model lib
libsentencepiece.a # SentencePiece tokenizer
libtokenizers_cpp.a # Huggingface tokenizer
libtvm_runtime.a # TVM Unity runtime
权重拷贝到App
./prepare_params.sh
Xcode 编译 App
修改证书,就可以用 Xcode 打包编译了。
什么是 TVM Unity Compiler?
TVM Unity Compiler是 Apache TVM 项目中的一个新框架,旨在提供一套架构,将各种优势组合起来,以优化机器学习模型在不同硬件平台上的运行效率。TVM是一个端到端的机器学习编译框架,支持多种前端库如TensorFlow, Pytorch, MXNet, ONNX等。TVM Unity框架通过引入新的技术路线,如Relax语言和相关的代码,以及对注册对象的管理(Registry::Manager),来增强其编译能力。此外,TVM Unity还致力于构建跨层机器学习编译器基础设施(Cross-Layer Machine Learning Compiler Infrastructure),以进一步提升机器学习模型的编译效率和优化能力。这表明TVM Unity Compiler不仅仅是一个简单的编译器,而是一个综合性的框架,旨在通过技术创新和架构优化,推动机器学习模型在不同硬件上的高效部署和运行。
其他上层工具
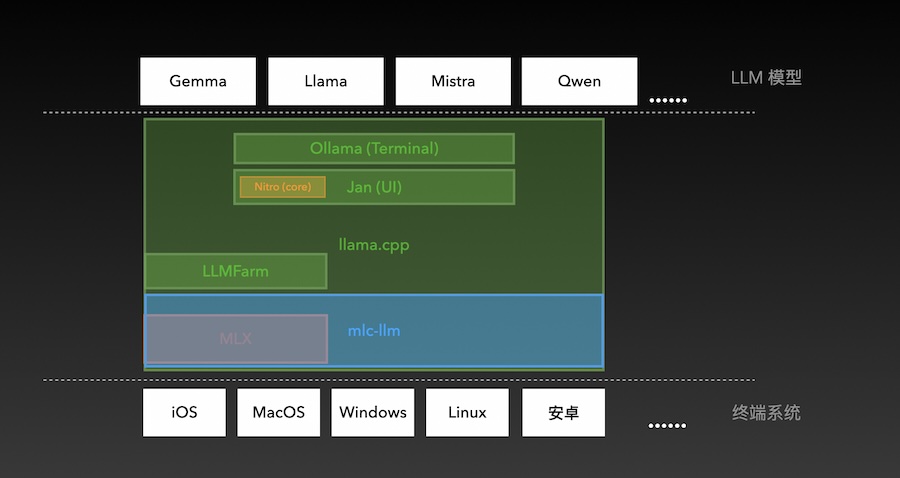
先放一张全局架构图,可以从上帝视角先一窥概况。
Ollama
关键词:GO 实现;命令行工具;本地服务器
基于各种现有的推理框架构建的一个 LLM 集成平台、社区(比如 gguf 的模型就会使用 llama.cpp 来推理),只需安装一个命令即可在本地快速和 LLM 对话。同时还会在本地开启一个 server,方面其他 chat UI 接入。
技术原理
依赖llama.cpp, 把 LLM 跑在 macOS, Linux, and Windows,用 GO 实现。支持导入 gguf, PyTorch or Safetensors 模型。
核心看这个配置文件Modelfile,这个是 Ollama 里的唯一配置文件,所有模型权重、推理参数、提示词模板都写在这里,可以认为是 Ollama 里最重要的文件。
其中 gguf在 Ollama 内部直接使用 llama.cpp 推理了。PyTorch 和 Safetensors 模型需要步骤比较多,需要借助 llama.cpp 这个工具先转换一下。
具体转换步骤:
转化模型:
python llm/llama.cpp/convert.py ./model --outtype f16 --outfile converted.bin(半精度 f16)量化模型:
llm/llama.cpp/quantize converted.bin quantized.bin q4_0(int4 位)编写
Modelfile:FROM quantized.bin创建
Ollama model:ollama create example -f Modelfile
然后你可以在命令行和这个转换后的模型对话了,或者在本地开一个REST API服务供其他应用使用,具体可以看 Github 主页。有了 API,因此市面就有很多 llama 的 GUI,例如:Ollama-SwiftUI、enchanted、chatbot-ui,生态就这么繁荣起来了。
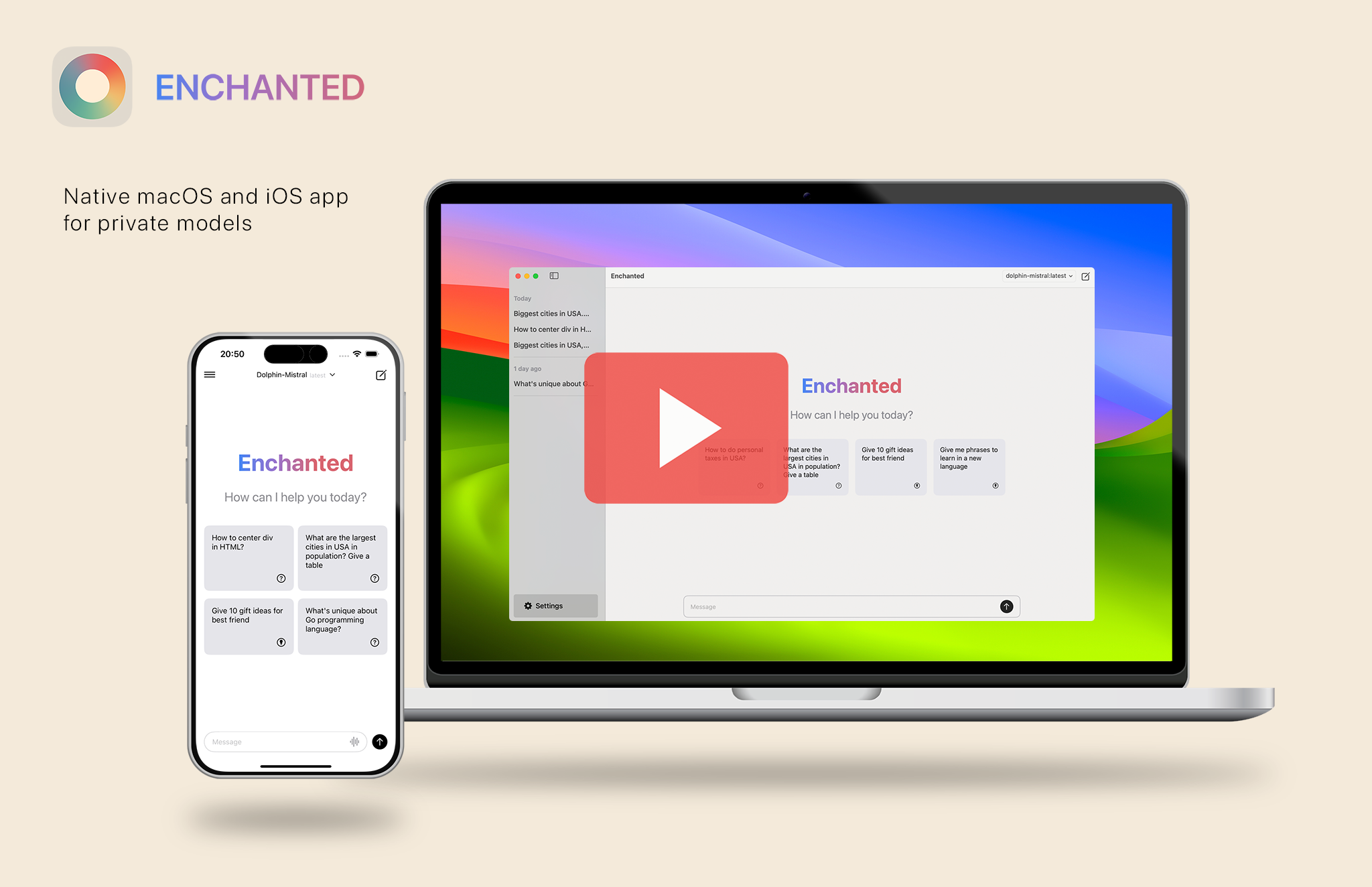
Jan
关键词:TS/JS;UI 体验流畅;性能佳
同样也是基于 llama.cpp 的 UI,一个非常好用的本地推理 electron 客户端。可以变成本地服务器。(性能应该比 Ollama 差一点)。BTW,Jan 基于 llama.cpp 做了个本地推理引擎 Nitro, 兼容 OpenAI 的 API,支持队列和伸缩,简化了 llama.cpp 的接入不走,可以轻松地接入线上产品(prod-ready)。
使用下来体验非常流畅,性能也没有损失,是目前我用下来最好的 llama.cpp UI。
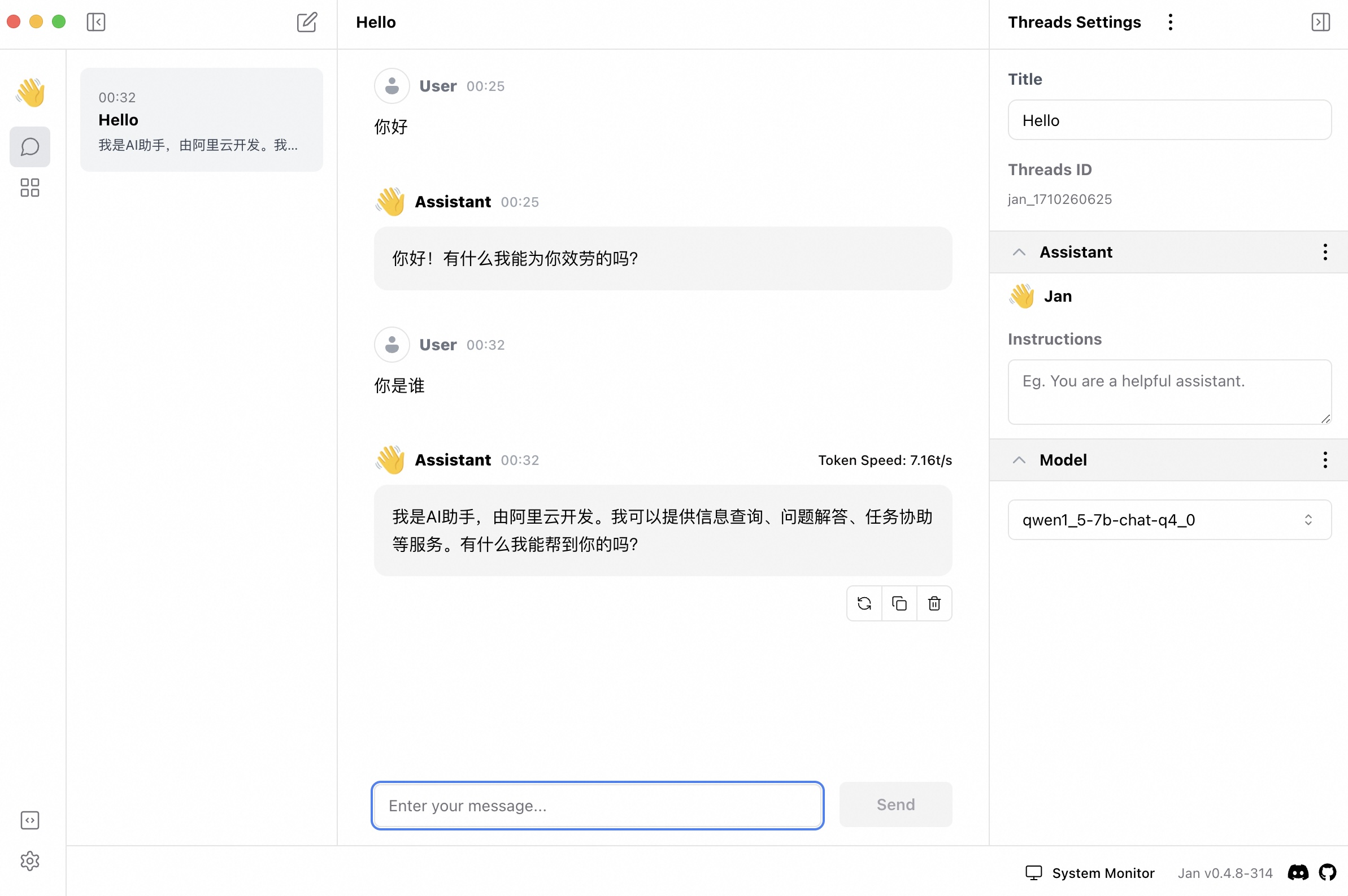
LLMFarm
关键词:Swift;UI 界面;体验流畅;性能佳
同样是基于的 llama.cpp,封装了 Swift 接口,为 Apple 平台专门优化的客户端工程。支持 ggjtv3 (must have a .bin extension) 和 gguf (must have a .gguf extension) 格式的模型。
这个项目专门优化了 Apple 平台的表现,能够部署到上 iPhone、Mac 上。实测下来,通过 llama.cpp 里面自带的 swiftui 项目无法在 iPhone 上跑 qwen2-7b 的模型,表现为直接 OOM;但是使用 LLMFarm 跑 7b 至少可以跑起来(虽然只有0.71t/s)
总结
以上就是目前开源社区端侧大模型方面的现状记录。最终再用一句话总结下,目前的旗舰手机能勉强跑 7B 的模型但速度极慢,几乎不可用(据说国内荣耀、OPPO 3月发布会的新机已经支持 7B 推理了,推测:1. 做了软硬件深度优化 2. 模型做了量化)。目前(2024年3月)要满足日常需求,旗舰的配置跑 1.8B 是最稳定的。按 scalinglaw 到今年9月的新手机,理论上就可以跑 4B 的模型;明年(2025年3月)行业一起努努力,就可以稳定跑 7B 模型。